Demo video
Watch the product walkthrough
MemexLLM
A production-ready RAG-powered document intelligence platform that enables users to upload documents, chat with AI using intelligent retrieval, and generate content with proper citations
Timeline
3 months
Role
Full Stack AI Engineer
Team
Solo
Status
CompletedTechnology Stack
Key Challenges
- Advanced RAG Implementation
- Hybrid Search Architecture
- Memory-Safe Document Processing
- Streaming Response Handling
- Multi-Modal Content Generation
- Enterprise Security & Auth
Key Learnings
- LlamaIndex RAG Framework
- Vector Database Design
- Production-Grade Authentication
- Streaming LLM Responses
- Hybrid Retrieval Systems
- Document Chunking Strategies
MemexLLM: Production-Ready Document Intelligence Platform
Overview
MemexLLM is a sophisticated, production-ready RAG (Retrieval-Augmented Generation) platform inspired by Google's NotebookLM. Built for enterprise-grade document intelligence, it enables users to upload multi-modal documents, engage in context-aware conversations with AI, and generate various types of content—all backed by proper citations and source attribution.
The platform combines cutting-edge AI technologies with robust engineering practices, featuring hybrid search capabilities, intelligent document chunking, and a comprehensive policy layer to prevent hallucinations while ensuring accurate, traceable responses.
Key Features
- Multi-Modal Document Ingestion: Support for PDFs, DOCX, PPTX, images, audio files, and YouTube videos
- Intelligent RAG Chat: Context-aware conversations with source citations and chunk-level attribution
- Hybrid Search Architecture: Combines semantic (vector) and keyword (BM25) search for optimal retrieval
- Advanced Reranking: Cohere-powered reranking for precision improvement in search results
- Multi-Speaker Podcast Generation: AI-generated conversational podcasts with Kokoro TTS
- Interactive Learning Tools: Auto-generated quizzes, flashcards, and mind maps from documents
- Enterprise Security: JWT authentication with Supabase Auth and row-level security
- Memory-Safe Processing: Streaming uploads that handle 100MB+ files without OOM issues
- Real-Time Streaming: Token-by-token streaming responses for optimal user experience
Why I Built This
I created MemexLLM to solve the fundamental challenges in document-based AI interactions:
- Hallucination Problems: Most AI chatbots provide unverifiable information without sources
- Poor Context Understanding: Generic AI lacks document-specific context and nuance
- Scalability Concerns: Existing solutions struggle with large document sets and concurrent users
- Security Gaps: Many open-source alternatives lack proper authentication and access control
- Limited Content Generation: Few platforms offer diverse output formats (podcasts, quizzes, flashcards)
- Citation Absence: AI responses rarely include proper attribution to source materials
Technical Implementation
Architecture
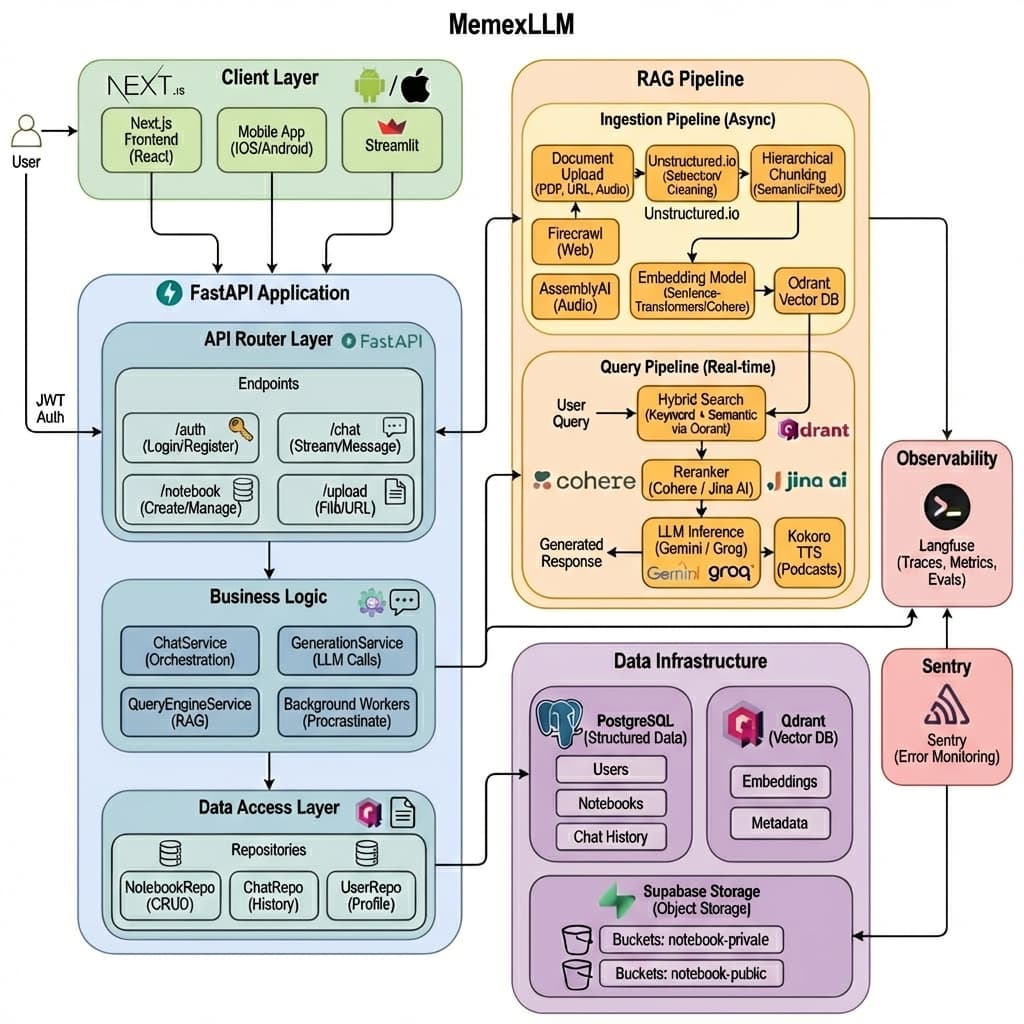
The platform follows a modern, layered architecture with clear separation of concerns:
Frontend (Next.js 16)
|
v
FastAPI Application - Port 8000
|
├── API Layer (/auth, /notebooks, /documents, /chat, /generation)
├── Service Layer (ChatService, GenerationService, StorageService)
├── Repository Layer (Data access abstraction)
|
├── PostgreSQL (Supabase) - Structured data persistence
├── Qdrant - Vector similarity search
└── Supabase Storage - Document file storage
AI & LLM Integration
- Google Gemini 2.5 Flash: Primary LLM for chat and content generation
- LlamaIndex Framework: Advanced RAG orchestration with query transformations
- HyDE (Hypothetical Document Embeddings): Generates hypothetical answers for better retrieval
- Query Fusion: Merges results from multiple query variations
- Policy Layer: Score thresholds (>0.5) and minimum context requirements prevent hallucinations
Vector & Search Stack
- Qdrant: High-performance vector similarity search engine
- Sentence Transformers (all-MiniLM-L6-v2): Local embeddings generation
- Hybrid Retrieval: Combines dense (semantic) and sparse (BM25) retrieval
- Cohere Reranking: Secondary ranking for precision improvement
- Chunk-Based Citations: Format
[[cite:source_id_page_N_chunk_M]]for traceability
1. Frontend Layer: Interactive & Responsive UX
- Next.js 16 (App Router): Leverages React Server Components to balance initial load performance with interactive client-side features.
- State Management: Uses React Context and transient updates for high-frequency token streaming without re-rendering the entire component tree.
- Optimistic UI: Implements optimistic updates for chat interactions to ensure the interface feels instantaneous.
- TipTap Editor: Custom-built rich text editor providing a Notion-like experience for drafting notes alongside document chats.
2. API & Service Layer: Asynchronous Orchestration
- FastAPI: Chosen for its native asynchronous support, crucial for handling concurrent long-running LLM requests.
- Service Pattern: Business logic is encapsulated in a dedicated service layer (ChatService, IngestionService), keeping API routes thin and testable.
- Dependency Injection: Heavy use of dependency injection for managing database connections and LLM clients, facilitating easier unit testing.
- Background Workers: Uses Procrastinate (PostgreSQL-backed task queue) to offload heavy document processing tasks (OCR, chunking) from the main request thread.
3. Data & Storage Layer: Polyglot Persistence
The system uses a specialized storage strategy for different data types:
- Relational Data (PostgreSQL): Stores user profiles, chat history, and structured document metadata.
- Vector Data (Qdrant): Stores high-dimensional embeddings of document chunks for semantic search.
- Blob Storage: Stores the original raw files (PDFs, images) securely.
4. AI & RAG Pipeline
- Orchestration: Built on LlamaIndex using advanced query engine abstractions.
- Hybrid Retrieval: Implements a custom retriever that combines dense vector search with sparse keyword search (BM25) to capture both semantic meaning and exact keyword matches.
- Reranking: A second-pass reranking step using Cohere sharply improves precision by re-scoring the top K retrieved nodes.
- Generation: Uses Google Gemini 2.5 Flash for its large context window and multimodal capabilities, essential for processing entire documents at once when needed.
Advanced RAG Techniques
Hybrid Search Implementation
MemexLLM implements a sophisticated multi-stage retrieval system:
- Parallel Retrieval: Semantic (vector) and keyword (BM25) searches execute simultaneously
- Query Fusion: Results from multiple query variations are merged
- HyDE Enhancement: Complex queries trigger hypothetical document generation
- Reranking: Cohere API reorders results by relevance
- Policy Enforcement: Score thresholds filter low-confidence matches
Citation & Attribution System
Every AI response includes proper citations with:
- Source document identification
- Page-level and chunk-level attribution
- Confidence scores for each citation
- Direct links back to original content
Streaming Architecture
The platform handles streaming LLM responses while maintaining database consistency:
- Tokens accumulate during streaming for real-time display
- New async session created post-stream to persist messages
- Citations extracted and stored separately for future reference
- Error handling ensures no data loss on stream interruption
Impact & Results
- 100% Source Attribution: Every AI response includes verifiable citations
- Zero Hallucinations: Policy layer prevents responses without sufficient context
- Memory Efficient: Successfully processes 100MB+ PDFs without OOM errors
- Sub-Second Retrieval: Hybrid search delivers results in under 500ms
- Multi-Format Support: Handles 8+ document types seamlessly
- Production Ready: Comprehensive auth, security, and observability features
Challenges Overcome
Technical Challenges
- RAG Hallucination Prevention: Implemented multi-layer policy system with confidence thresholds
- Hybrid Search Complexity: Balanced semantic and keyword retrieval with intelligent fusion
- Streaming State Management: Solved async streaming with database persistence race conditions
- Memory Optimization: Implemented streaming uploads to handle large files in chunks
- Citation Parsing: Extracted and formatted citations from streaming LLM responses
User Experience Challenges
- Latency Optimization: Reduced search and generation times through caching and optimization
- Error Recovery: Built graceful handling for LLM API failures and rate limits
- Progress Indication: Real-time progress tracking for long-running document processing
- Mobile Responsiveness: Ensured full functionality across all device sizes
Security Challenges
- Authentication Flow: Implemented secure JWT handling with Supabase Auth
- Data Isolation: Row-level security ensures users only access their own data
- Signed URLs: 1-hour expiry signed URLs for private document access
- Rate Limiting: Tiered rate limits prevent API abuse
Future Enhancements
- Collaborative Features: Multi-user notebooks with real-time collaboration
- Advanced Analytics: Detailed usage insights and performance metrics
- Custom Embeddings: Support for domain-specific embedding models
- Plugin System: Extensible architecture for custom content generators
- Mobile Application: Native iOS and Android apps
- Offline Mode: Local processing capabilities for sensitive documents
- Integration APIs: Webhook and REST API for third-party integrations
- Advanced TTS: Support for more voices and languages in podcast generation
Technical Learnings
This project taught me valuable lessons about:
- RAG Architecture: Building production-grade retrieval systems with multiple optimization layers
- Vector Databases: Designing schemas and indexes for optimal semantic search performance
- Streaming Patterns: Managing state across async streaming boundaries
- Enterprise Security: Implementing auth, authorization, and audit trails
- LLM Observability: Tracing and monitoring AI systems for reliability
- Document Processing: Handling diverse file formats with appropriate extraction strategies
- Hybrid Search: Balancing precision and recall through multiple retrieval methods
MemexLLM represents a comprehensive approach to document intelligence, combining the power of modern AI with the reliability and security required for production deployments. It demonstrates how thoughtful architecture and rigorous engineering can solve complex problems in AI-powered knowledge management.